
|
|
|
Volume Three - Spirit Boxes And Similar Wastes Of Time And Money
Ever Wonder WHY No Two People Hear The Same Message on a Spirit Box???
Ghost Boxes and related devices that assemble bits of speech together.... It is a method being used by some ghost hunters today that claim to allow spirits to speak to them. Some claim to get direct answers to questions posed; some claim spirit contacts can provide advice or other information. Some of the less scrupulous even charge clients to capitalize on these claims by providing a conduit for their relatives to contact them via one of these devices. And the serious researcher pooh-poohs the whole idea, calling the concept a sham and a fraud. Or worse.... This report outlines in detail how speech functions, the theory behind how these devices really function based on proven scientific concepts, and will demonstrate the difficulty in doing what is claimed for them. It will outline what any prospective spirit would have to do to actually accomplish such communication. The reader can form his own opinion of the possibility of any of them doing what they claim. What Is Speech? How Is It Generated? To understand the concept of how speech is assembled first you must understand what speech is. For this discussion all you need to comprehend are the basics, so I won't delve into allophones and some of the more complex speech characteristics. Speech is simply a group of patterns formed into words which convey a message. These patterns are called phonemes. They are divided into two primary types; vocalizations and fricatives. Vocalizations are the sounds made by the larynx; fricatives are created by the position of the tongue and lips. There are about 60 phonemes in the English language, however reasonably intelligent speech can be accomplished using only about 30 of these since some inflections are combinations of sounds. To get an idea of how this works simply slowly make a statement and note the position of your tongue and lips, along with the sound from your throat as each sound is formed. Early attempts to synthesize speech were difficult. While the sounds could be generated easily enough, assembling them became an issue. Switching could not be done fast enough to make words which could be clearly heard and understood. So until the advent of the microprocessor electronic speech was difficult to attain. But in the mid 1980s the first speech synthesis became practical. One of the first of these synthesizers was the General Instruments SPO256 series. These were phoneme based and actually did a reasonably good job at generating electronic speech. (Remember the old robotic speech your computer used to make?) The 256 chip generated about 60 phonemes (allophones) that could be addressed and assembled as needed to form virtually any word in the English language. When paired with a microprocessor the assembly was fast enough to sound good, if somewhat mechanical. Table 1 below provides a list of these phonemes and the code needed to address them. A sample word for each allophone is provided as well. Note that some duplication exists; this is to allow for slightly different inflections needed for certain words 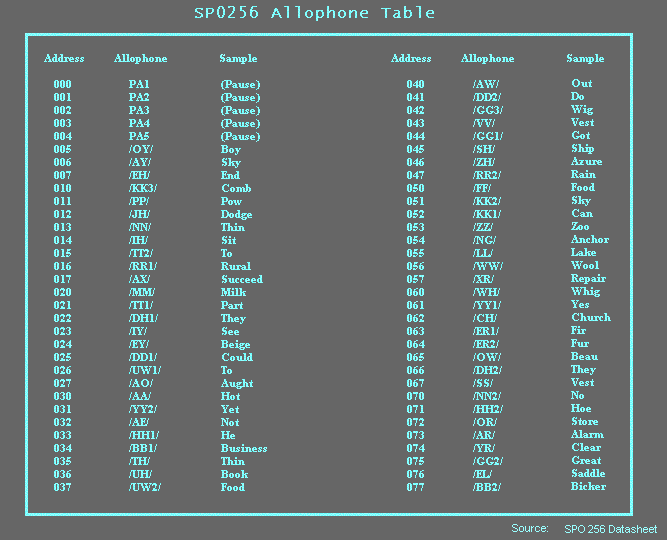 Clearly the concept of assembling phonemes to create speech is possible and has been done successfully for some time now. In fact, it is rather archaic, today's electronic speech has taken actual human voice and has assembled words and phrases in that manner rendering phoneme based synthesis obsolete in most cases. So for sake of this discussion we actually need to take a step backward to the mid 1980s, since phoneme based assembly represents the techniques of the spirit devices we are discussing.
So How Does A Ghost Box Work? There are two major differences in these devices. The original Frank's Box and the later Shack Hacks, PSB series of devices, etc. obtain bits of speech from the radio broadcast bands, the Ovilus and those like it synthesized speech using phonemes and built the words and phrases internally in the manner we just discussed above. Later versions of both types have added other "features" that simply make them look or sound more impressive. But what would a spirit need with echo or reverb? For our discussion I will stick with just the basics. The other stuff is just another way to induce pareidolia in the listener.. First, let's look at Frank's Box and those which tune radio broadcasts. Certain differences may be apparent, but unless noted the basic concept is the same. In their simplest form, all take radio signals from the air and scan through the various frequencies, breaking the broadcast audio apart into various snippets of sound much like the phonemes that originally made up the words. One inherent problem however is that the receiver is in no way synchronized with the audio, so the "phoneme" heard is not a true representation of the original. A part of one sound may overlap and become a portion of the next when the transition between stations takes place. This may result in sounds which are combined in a manner not keeping with normal speech patterns. Keep this in mind as this discussion proceeds. The key component of the box is a random voltage generator. This creates a rapidly changing voltage which is supplied to the digital tuning input of a radio chip. Filtering and limiting is done to cause these changes to occur 8 to 10 times per second. (The "Scan Rate") The importance of this rate will become apparent later in this discussion. The changes in voltage cause the tuner to quickly change the station being received. The claim is that the station will provide the required phoneme needed to be assembled into a particular word, thus a message is created. Some of these devices also include an "echo box" on the output of the radio receiver to provide acoustical filtering. The proponents of this idea say this filtering helps to improve the quality of the voice being received. (Or might it be to cover the transition and further confuse the listener by making the sound flow better?) There is another factor that must be entered into the discussion. Since this switching is done at a rate which is audible, a small pop sound occurs each time a transition occurs. This means that each of the phonemes created generally start with a weak, but noticeable, "p" sound. The importance of this will become apparent as we go on. From a strictly technical point of view, when properly built these boxes do exactly what the developers claim; they tune between radio stations several times per second creating a series of noise bursts that are derived from radio broadcasts. For sake of discussion let's consider an exercise in the application of this concept. An Exercise in Speech Creation In our experiment, we will assume that the box is working as claimed. For simplicity we will assume that there are several radio stations nearby, and the box is capable of receiving all of them. A transcription of the program from each of these stations is shown on each row of the chart below. At any given instant each station is broadcasting the phrase shown in its row. Time is charted across the top. The chart represents a period of just a few seconds of broadcast time, each column displaying a transition in the tuned frequency by the ghost box. Each column is one pulse as the box does its scan. The box is adjusted to scan at a 100ms rate, so each column progresses from left to right at that interval. You can go to any column to find exactly what each of the stations are broadcasting at any given instant in the scan cycle. Two other rows are also provided. These represent a "sh" sound of random noise often heard on the broadcast bands. It's the sound heard when the receiver is tuned to a frequency between stations, and a blank line which represents a frequency being quieted by some external source. You can use each of them as needed to help you create your response. Now for the task at hand. You are the spirit haunting the graveyard. The investigator, sporting a ghost box, has just asked you a question, "What is your name?" Using the available radio stations given in the chart below, you can use the ghost box to reply. All you need to do is select one phoneme from each sequential column, left to right, in order to assemble the word or phrase you want to speak in order to answer the question. Since time is sequential, you must pick one, but only one phoneme from each column to build your word. Thus you may only check one station in each column. (Remember, Ghost Boxes are only capable of tuning only one station at a time!) You can use the "sh" sound or the quiet (no sound, pause) instead of any station if that fits your needs. You may also use any station as often as you want since it is possible for the ghost box to hit on a station multiple times. Feel free to repeat this as often as you wish, since there are literally thousands of possible combinations! If you wonder about the uneven spacing, remember, some people speak faster than others, thus a transition period may allow two phonemes to occur at times.! It may also allow for only a portion of a phoneme to be broadcast if the station is cut off by a transition midway through its time period. 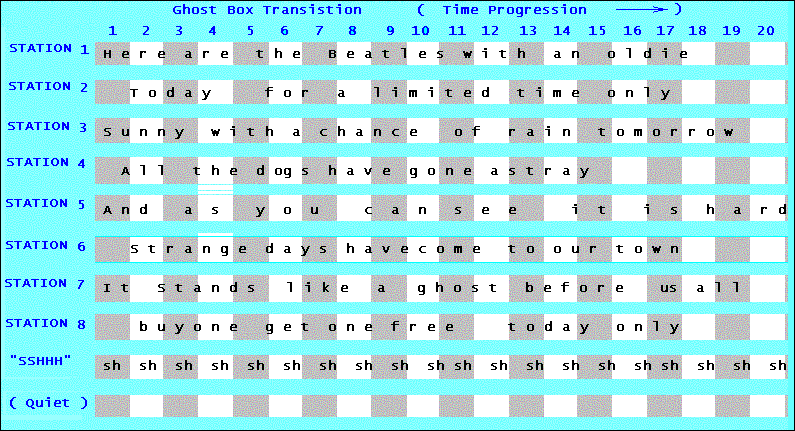
Not as easy as you thought, is it? Also consider that each of these stations may have had different announcers, male and female, speaking with different inflections. One may be speaking softly, the next screaming at you! And a couple may have actually been singing the phrases! You, as the spirit trying to assemble your word have to consider this as well. But the biggest advantage with this is something you have that a spirit attempting this would not. Even assuming the spirit could know what each station was broadcasting, you have the ability to look at the phrase and know what was going to be said before it was actually broadcast. You can pick and choose by comparing each column. Our real world spirit would not have this benefit since only each announcer would know what he was going to say before he said it. There is one more thing to make note of. Remember the soft "p" sound mentioned earlier? At each transition that may be heard as a part of the phoneme. (It's the "P - P - P - P" heard as the scan takes place.) Since it is a low volume it is not a major factor if the radio snippet is a fairly loud one. But if a silence or low volume snippet is present this will significantly alter the context at each transition. It may even cause a phoneme to sound like something else. If you want to try another exercise, go back to the chart above and insert a "p" at each transition. See what possible answers you can get to the question posed to the spirit. The next problem our spirit faces is a matter of speed. Keep in mind that the Ghost Box is transitioning between stations every 100 milliseconds. That means that the spirit assembling these phonemes must complete the selection and decision process at least 10 times every second, or at the normal rate phonemes are assembled in a normal speech pattern. That doesn't leave much time for consideration! Since the ghost box sets the transition rate the spirit will be obligated to keep up with it. A final problem must be addressed. Even if our spirit were able to perform the transitions quickly enough there are two more questions that need answered. First of all concerning the tuning voltage itself. The chip used for tuning the radio stations is set to the desired frequency by placing a DC control voltage on its tuning input pin. This voltage must be very precisely controlled; even a deviation of just a few millivolts will cause the tuner to fail to select the desired station. This is probably the most critical operation these boxes perform. So, lacking a voltmeter and any kind of direct feedback, how does our spirit place this precise voltage on that pin? And for that matter how does the spirit even generate such a steady state voltage? And remember, to coincide with the transition rate the spirit must change this voltage to its next value seamlessly for every phoneme it wishes to generate. Since this is a key component in the operation of these boxes, this question must be addressed and answered to validate their operation. I leave it to the believers in these devices to address that issue. And if you are going to say it just happens, then you should be prepared to explain a method to attain this seamless operation in real time.
Interpretation of the Speech Patterns. Is It Pareidolia? So let's move on. This section applies not just to Ghost Boxes but all EVP. One of the things many encounter when they attempt to decipher any EVP or other alleged spirit voice is the quality of the audio. Seldom does anything come across clear. It is usually subject to interpretation by the listeners, and often you get as many different interpretations as you have listeners. One way to help prevent errors in this area is to use the same policy recommended for EVP recordings. This is known as the Rule of Three. The Rule of Three simply states that any recording made be played back to three independent listeners. It must not be altered or otherwise "cleaned" or filtered. The listeners must not have been prompted in any way as to the content of the audio. If all three hear the same thing, the chances are good you have something worthy of further study. If two of the three hear nearly the same thing, it is remotely possible it is as heard. If none of the three agree, you have a clear case of audio pareidolia. Toss it out. So what might cause the Ghost Box to create audio pareidolia? One of the main causes is the transition itself. If one views the chart we used for the exercise, you see that in some cases phonemes of the words in each station fall directly on a transition point. This results in a partial phoneme, not a true representation of the phoneme. Thus we have phonemes generated which are not even valid for speech. And don't forget to add in that "p" sound on occasion! A second source of pareidolia has to do with the transition timing. The cadence of the transitions mimic the pattern of speech. Thus it is an easy matter the brain to be fooled into hearing speech. The rhythm is there, all that is needed is some noise and you have a phoneme. And the human mind will work overtime to make sense out of chaos. There is much more on Pareidolia covered in Volume 4. For EVP work we are only concerned with audio. Pareidolia affects all our senses to some degree, and conditioning can affect what we expect to hear. This too alters our perception of reality. It can cause us to interpret noise based on what we expect and we have a case of pareidolia. Are You Saying These Ghost Boxes NEVER Detect Anything? Not at all. Many of the statements made above would lean toward the idea of a spirit using a ghost box was impossible. However there is a very possible way a ghost box might be detecting speech. It's just not the way that is claimed for them. I built a copy of Frank's Box some time ago using plans provided online. The plans utilized a perf board and jumper leads connecting the various components. (Though I have the ability to actually design and build PC Boards in my lab, I kept it as near to Frank Sumpton's original methods as I could.) Point to point wiring techniques were employed as specified. Once built I subjected this device to testing in a lab environment. Needless to say shielding was virtually non-existent. The control circuitry was relatively immune to outside interference, but the audio circuitry was quite another story. Stray RF easily coupled into the audio stages. In fact strong radio transmissions could be heard directly over the internal speaker. These transmissions, since they were picked up directly instead of using the tuner chip, did not require phoneme assembly or anything else. The level was low, often the signal from the tuner covered it. But having an actual voice just under the phoneme based noise allowed certain intelligible words to come through. In other words it was very susceptible to outside interference! One test I subjected my ghost box to was to determine exactly what stations were responsible for the phonemes being generated. To accomplish this I made a modification to the original plans. I brought out a test point from the tuning input pin on the radio chip. This allowed me to measure the precise voltage being generated by the Random Voltage generator. Since this is used to tune the radio I could determine the precise frequency the tuner was set to at each transition. The voltage was scanned by a high speed data logger so a precise track could be made of what frequency was selected at each transition. Thus it became a simple matter to use the frequency and compare that to what station was broadcasting on that frequency. The station could then be contacted and a comparison made with their actual programming at the time. When I ran my test I got the expected stations and their broadcasts with one notable exception. On the quieter segments one voice could be heard in the background. Several times the voice coincided with a phoneme being detected; other times it was much lower in amplitude. And even more remarkably the voice sounded a lot like Rush Limbaugh! Now since I don't believe I was in direct contact with him, my next step was to compare the times when the phonemes matched the background voice. At those times I found the tuner was actually selecting a local AM station near here. A quick call to the station's program director confirmed that at the time of my test Rush Limbaugh was indeed on the air. Thus the source of both the stray RF and the phoneme was confirmed. Based on that test I can say conclusively that the ghost box is susceptible to outside RF interference, and as such could pick up voices that might be mistaken for spirit communications. Of course improved shielding might prevent that form of interference, but from what I have seen of various ghost boxes not much effort goes into providing that level of isolation. In fact many claim the lack of shielding is what actually makes them work! Using the results of my test the fallacy of that statement is clear. There is an easy way to confirm if you are simply picking up interference. This interference by its nature MUST be an audio frequency since it is coupling in after the radio stages. Thus even while the radio is pulsing through, the voice coming in as audio will not change. It is not coming through the radio tuner, rather directly to the analog audio stages. It won't scan, instead being present along with the scanned noise.  An Assortment of Pareidolia Boxes ! Conclusions After going through the testing and evaluating the results of different devices several things become apparent. First, by using the transition rate similar to speech all have set the groundwork for auditory pareidolia. All also create noise which is a second requirement. Third, this noise is not random, instead it actually mimics and even duplicates speech patterns in many cases. Thus all of these devices encourage the formation of pareidolia in the listener. But even more revealing is the mindset of many of the users. They fail to properly critique their own results, instead believing that spirits are speaking with them. The forming of such preconceptions is poor investigative practice in general, not just regarding ghost boxes. As with EVP, asking questions requiring a single word response, especially "Yes-No", promotes false positives. Coupled with the fact that many of these devices can easily produce an "S" sound from the static between stations, and the listener's pareidolia, a "Yes" response is not only possible but very probable. That coupled with a propensity to ignore sounds that don't fit results in many claims about how effective these devices are. In reality, when confronted with the facts their usefulness quickly fades. They simply become what they are, gimmicks and games for entertainment, not serious communication devices. Many manufacturers actually state in their user literature the device is "for entertainment only." To their credit they recognize that aspect of their product and are being truthful. The problem is with some of us who fail to read their disclaimer and accept this a "Scientific Investigation".
© MAY 2024 - J. Brown |



